
Big data refers to sizeable live information that is created each moment on the web through different assets with fast speed. It can be text, images, videos, social media, medical domains.
This leads to the requirement of data processing software come into existence. One among the main and on-request systems satisfying the errand as per the expanding information is none other than the Apache Spark.
Apache Spark
Apache Spark is most actively developed open source project in big data and probably the most widely used as well.
Spark is a general-purpose Execution Engine, which can perform its cluster management on top of Big Data very quickly and efficiently. It is rapidly increasing its features and capabilities like libraries to perform different types of Analytics.
Apache Spark at that highest level is the only open-source framework that combines Data and AI. So, using Spark, one can-do large-scale data transformation and analysis and can immediately implement state-of-the-art machine learning and AI algorithms on it.
Most importantly in building AI paradox, AI is the best only the day you applied it in paradox and is powered by data.
There, if we come with an integrated open-source framework that can manage both designs as well as time parallelly, you can quickly build the highest quality application.
This is the primary reason why we choose “Apache Spark”– the leading open-source framework to process Big data.
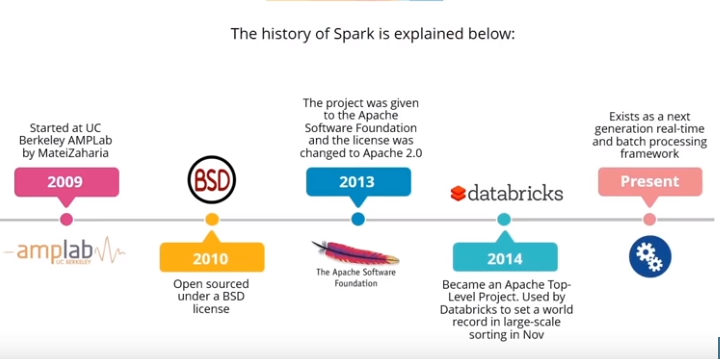
Apache Spark’s Abstraction:
Here are some tools to process big data in the Apache Spark solution. The client can be either designer, planner, specialized individual, and so on.
- RDD (Resilient Distributed Dataset): The distributed data processing and its transformation all are managed by RDD, and that’s why apache does most of the handling in terms of the change and maintaining the data lenient. It is immutable.
- DAG (Direct Acyclic Graph): When you run an application within Apache Spark, it constructs a graph, comprising nodes and edges, and creates a sequence of computation to process data.
- Spark context: Spark context is the entrance of the Spark functionality and who performs this function is named “Spark Driver’, who generates Spark context. It empowers the Spark application to get to the sparkle bunch with the assistance of the Resource Manager.
- Transformation: While performing certain activities like creating a filter, mapping operations leads to a generation of a new RDD, which is collectively called a Transformation.
- Actions: Anything within Spark is done through a process of lazy loading, which means, whenever a dag is created it does not don’t perform any computation/execution of the underlying data, till it is required. This is why it is called a lazy loads process, but comes with numerous benefits in the form of resilience. If somebody wants to collect or extract the data and get its count is called the action.
Advantage of Apache Spark:
- Process Data in Real-time
- Handle input from multiple sources
- Easy to use
- Faster Processing
- Inbuilt machine learning libraries.
- Fast in-memory computation
- Helps for streaming data, interactive and declarative queries etc.
Some tips and tricks for Apache Spark
So, after discussing the Spark features, I am interested in sharing some tips and tricks for better performance. Let’s begin
1) Try to Avoid using custom UDFs (User Defined Function):
The feature of Spark SQL is used to define new functions to work with columns. That expansion the vocabulary of Spark SQL DSL for changing datasets.
The primary reason to avoid using UDFs is behind the Screen, the Enzymes that cannot process and Optimize UDFs are treated as a black box, which results in losing many optimizations like -predicate, pushdown, etc. Therefore, avoiding UDFs is suggestible.
2) Always try to see how Software goes about transmitting:
Call the explain () method when you use the Data frame or Dataset object.
For e.g., dataset.explain(true) – “Checking the output of this function is the Correct way to notice wrong executions.
3) Resolving local hostname:
When organizing issues happen Sparks can’t resolve your IP address or neighbourhood hostname, use this for custom hostname- SPARK_LOCAL_HOSTNAME and for custom IP SPARK_LOCAL_IP
The WARN messages may show up in the log when Spark completed the settling procedure:

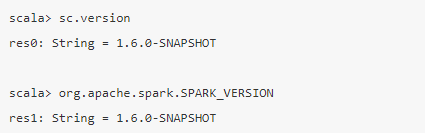
4) Spark version in Spark shell:
In Spark, shell writes sc.version or you may code like org.apache.spark.SPARK_VERSION to know the version of Apache Spark.
5) Spark shines increases due to TUNGSTEN:
Tungsten is one of the significant factors improving the efficiency of Spark execution. Using Tungsten Spark operation, the user can directly work at the byte level of memory management, code generation, and specific wire protocol.
6) Launch command of Spark Scripts:
Using this SPARK_PRINT_LAUNCH_COMMAND
Check whether the Spark launch command is displaying the standard error output code i.e. System.err or not. Sparkle shell contents utilize this direction organization.apache.spark.launcher.
Main and the class inside checks SPARK_PRINT_LAUNCH_COMMAND to set any esteem which will print out the whole order line to dispatch it.
Conclusion:
Apache Spark is the popular and most Advanced product of the Apache community, which provide the chance to work with streaming data.
It is supported programming language and increasing momentum in terms of the product community using R and Apache Spark together.
Also Read: