

Most conversations about big data start in the wrong place. They open with volume statistics, or platform comparisons, or vendor case studies dressed up as strategy.
What rarely gets said plainly is this: big data architecture is a design problem before it is a technology problem. The tools are secondary. The thinking comes first.
Every organisation accumulating data at scale — and in 2026, that means nearly every organisation of any consequence — eventually confronts the same core question. How does raw, chaotic, high-velocity data get shaped into something that produces reliable decisions?
The answer lives in architecture. Get the structure wrong, and even the most sophisticated tooling produces expensive noise. Get it right, and the competitive distance between a data-driven organisation and one still running on gut instinct becomes almost unbridgeable.
What follows is not a platform checklist. It is a genuine examination of how big data architecture works, where it breaks, and what separates well-designed systems from the ones that quietly rot from the inside.
Architecture Is a Set of Decisions, Not a Product
This distinction matters more than it seems. Vendors sell platforms. Architects make decisions. The two activities are not the same, and confusing them is how organisations end up with bloated infrastructure that solves yesterday’s problem at tomorrow’s cost.
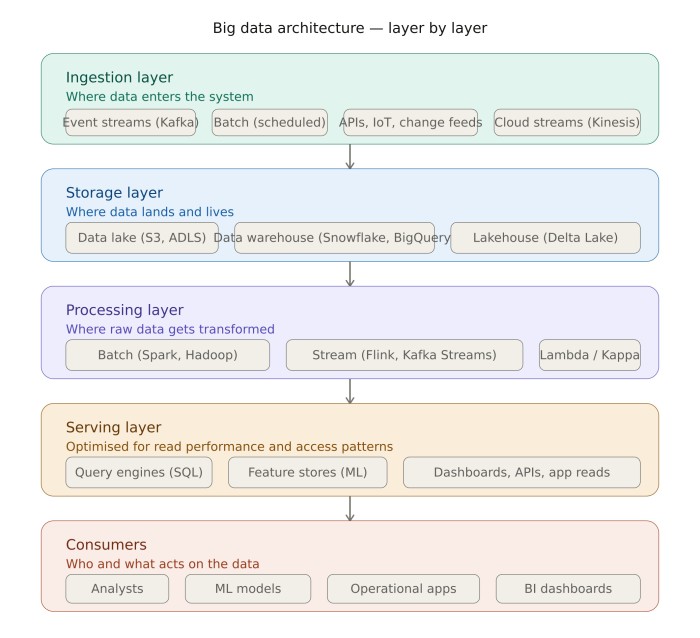
Big data architecture is the end-to-end framework governing how data moves — how it enters a system, where it lands, how it gets transformed, and how it ultimately reaches the people or systems that act on it.
Every decision in that chain carries trade-offs. Speed against accuracy. Flexibility against governance. Cost against latency. Real-time against batch.
The classic framing from analyst Doug Laney — the three Vs of Volume, Velocity, and Variety — still holds as a diagnostic lens. Petabyte-scale storage requirements demand different design choices than gigabyte-scale ones.
Sub-second latency requirements rule out entire categories of processing approaches. Unstructured data from image feeds or audio logs calls for fundamentally different storage and indexing strategies than clean relational tables. Knowing which Vs dominate a specific use case is the precondition for every good architectural decision that follows.
The Layers Beneath Every Big Data System
Sophisticated architectures look complex in diagrams. The underlying logic is more straightforward. Nearly every big data system, regardless of scale or industry, organises itself around the same functional layers.
Each layer has one job. When layers bleed into each other — or when one gets neglected — the whole system degrades.
1. Ingestion
Ingestion is where data enters. The design challenge here is not just throughput. It is reliability under failure conditions. Sources disappear. Schemas change without warning. Volume spikes arrive at inconvenient moments.
Tools like Apache Kafka have become near-standard for high-throughput event streaming precisely because they handle these edge cases gracefully — decoupling producers from consumers, persisting event logs, and allowing replay when downstream systems fall behind.
For batch ingestion, where real-time delivery is unnecessary, the design priorities shift toward scheduling reliability and efficient resource utilisation.
2. Storage
Storage sits beneath ingestion and carries the heaviest long-term cost implications. The modern default is a two-tier approach: a data lake for raw, schema-flexible storage (typically on cloud object storage — AWS S3, Azure Data Lake, Google Cloud Storage), and a data warehouse for structured, query-optimised analytical data.
Platforms like Snowflake, Google BigQuery, and Amazon Redshift have matured significantly, offering separation of compute and storage that makes cost management tractable in ways legacy on-premise warehouses never could.
The data lakehouse pattern — pioneered by Databricks through the open-source Delta Lake format — attempts to collapse this two-tier structure into one. The promise: raw lake flexibility with warehouse-grade ACID transactions and query performance.
Whether the promise holds depends heavily on workload characteristics. For organisations with diverse, messy data that also needs to support fast analytical queries, the lakehouse pattern has proven its value in production.
3. Processing
Processing is where architecture decisions become most consequential for business outcomes. Batch processing — transforming large data sets on a defined schedule using frameworks like Apache Spark — suits workloads where some latency is acceptable and accuracy matters most.
Stream processing — continuous, event-by-event transformation as data arrives, handled by tools like Apache Flink — suits use cases where minutes or seconds of delay carry real cost.
Fraud detection. Dynamic pricing. Real-time personalisation. Operational monitoring. These are stream processing problems. Monthly financial reporting is not.
The serving layer is frequently the most underinvested. Data that has been ingested, stored, and processed still needs to reach its consumers — analysts, dashboards, ML models, operational applications — in a form optimised for their access patterns.
Read performance here matters differently than write performance at ingestion. The same data may need to serve multiple consumers with completely different latency and format requirements, which is what makes serving layer design genuinely difficult.
Lambda, Kappa, and the Architecture Pattern Debate
Two patterns have shaped how practitioners think about big data system design for the better part of a decade. The debate between them is a useful proxy for broader architectural trade-offs.
Lambda Architecture
Lambda Architecture, introduced by Nathan Marz, runs two parallel processing paths: a batch layer that reprocesses all historical data with high accuracy, and a speed layer that handles incoming real-time data with acceptable approximation.
A serving layer merges both views for queries. The result is a system that is simultaneously accurate and fast. The cost is operational complexity — two separate codebases doing conceptually similar work, diverging over time as teams maintain them independently.
Kappa Architecture
Kappa Architecture, proposed by Jay Kreps, cuts the Gordian knot by eliminating the batch layer. Everything is a stream. Historical reprocessing happens by replaying the event log through the same streaming pipeline. Operational simplicity improves substantially.
The trade-off is that stream processing systems must handle the full complexity of the workload without the batch layer as a fallback.
For teams with strong streaming expertise and use cases where the event log is naturally replayable, Kappa is genuinely superior. For teams without that foundation, the simplicity argument can become a liability.
Most production architectures today borrow from both, shaped more by team capability and existing infrastructure than by theoretical purity.
The Failure Modes Nobody Talks About Enough
Architecture failures in big data systems rarely announce themselves loudly. They accumulate quietly — in slow query times, unreliable reports, mounting infrastructure bills, and data that nobody quite trusts.
1. Data swamp problem
The data swamp problem is the most common. Data lakes fill rapidly when ingestion is easy and governance is hard.
Without metadata cataloguing, data lineage tracking, and quality enforcement at the point of entry, lakes become repositories of files nobody can confidently identify or rely on.
Apache Atlas and commercial platforms like Alation exist specifically to address this. The mistake is treating them as optional add-ons rather than foundational requirements.
2. Speculative over-engineering
Speculative over-engineering burns engineering budget on scale problems that may never materialise. Building for exabyte-scale when current data is in the hundreds of gigabytes is not prudent planning — it is a failure of prioritisation.
Good architecture is proportional to current needs with clear, documented upgrade paths. It is not a monument to hypothetical future requirements.
3. Cost architecture neglected at design time
Cost architecture neglected at design time produces bill shock. Cloud storage costs appear trivial per gigabyte in isolation.
Data egress fees, query scan costs on services like BigQuery, hot versus cold storage tiering decisions, and compute cluster sizing all interact in ways that generate surprising monthly invoices.
Organisations that model cost architecture as rigorously as they model performance architecture avoid this. Those that don’t, learn expensively.
Where Big Data Architecture Is Heading
Data Mesh is the most significant structural shift in how organisations think about data ownership. Rather than centralising all data engineering into a single platform team — which creates bottlenecks as data volume and organisational complexity grow — data mesh distributes ownership to the domain teams closest to the data.
Each domain treats its data as a product: owning quality, documentation, and access contracts.
The technical infrastructure to support it — federated governance, self-serve tooling, standardised interfaces — is still maturing, but adoption is accelerating in large enterprises.
Feature stores are reshaping serving layer design for organisations running machine learning in production. The problem they solve is real: ML models need consistent, low-latency access to computed features, both during training and at inference time.
Building that infrastructure from scratch is significant engineering work. Platforms like Feast and Databricks have productised the pattern, and feature stores are increasingly standard components in data architectures supporting production ML.
The convergence of batch and stream processing into unified APIs is narrowing the gap between Lambda and Kappa in practical terms.
Apache Flink’s batch execution mode and Spark’s continued investment in structured streaming are moving toward a future where the same codebase handles both paradigms without compromise. That convergence will simplify architectures significantly when it fully matures.
The Discipline Behind the Design
Big data architecture rewards practitioners who treat it as an ongoing discipline rather than a one-time infrastructure project. Data volumes grow. Business requirements shift. Technologies mature and get replaced.
The architectures that hold up over years are the ones built on clear design principles — proportionality, governance from day one, explicit trade-off documentation, and a preference for operational simplicity over theoretical elegance.
The organisations extracting genuine value from data are not necessarily the ones with the largest budgets or the most advanced tooling.
They are the ones that built architectures matched to their actual problems, kept complexity in check, and understood that trust in data starts at the ingestion layer, not the dashboard.
Also Read: